
「ChatGPT Meetup Tokyo #0」に参加してきました。後編は事例登壇が多く、ビジネスの参考になりました。前半のブログはこちらです。

YouTubeのアーカイブ動画はこちら。
ローカルLMMは使えるか?~性能、展望、ホスティングと費用 乾夏衣
GPUが大好きで、自宅にはたくさんのGPUサーバーがあるようです。このサーバーを利用したくて、ローカルLLMを触ってみた、ということでした。
LLMはVicuna-13であるため、GPT3.5クラスであるが、ファインチューニングで良い結果をだせる。
ざっくり、 わかったこと。
・現時点で、GPT-3.5相当なら民生品のサーバーで動く。
・GPT-4のEvalでvicuna-13bが最もgpt-3.5-turboに近い。
・おそらく、今年中に3.5相当にアラインされたものが使えるようになる。
・たった13bのパラメータでGPT-3.5っぽいことができる。
・基盤 LLMの性能よりも、fine-tuning (instruction-tuning) が大事であり、性能の差につながる。
・LLMはただの言語モデル。GPT-5よりあとの世代で仮にLLMパラメータの限界を迎えたとしてもinstruction-tuningの手法の進化でいくらでも頭がよくなっていく?
・Sam Altman が GPT-4 よりパラメータ数を増やすことはないと言っているが、おそらくこの点に言及しており、これ以上GPTが賢くならない、ということではない。
GPT のパラメータ数予想
gpt-3.5-turbo、 gpt-4 がなぜこんなに安いのか?個人的な予想として、以下を考えている。
・gpt-3.5 turbo=10-30b 級の蒸留モデル
・gpt-4 = 300-500b 級の新規モデル
・さらに、 OpenAI は原価ベースでAPI を提供している
Microsoft が出している推論最適化ライブラリのレポジトリ表によれば、 A100で176b-int8 のモデルを用いて100万トークン (=1000k token) を出力するために、最適な設定で $176 かかるそうです。つまり、$0.176/k token となり、GPT-4のざっくり2倍のコスト。

GPT はもっと賢くなります
Sam Altman は GPT-4以上のパラメータにしないと言っていましたが、ただ単にパラメータを増 やさないと言っただけです。
油断してはいけません。現時点で想像できること。
・頭を良くする方向 ⇒Fine-tuning の技術の向上により、よりロジカルな思考ができるようになる。
・使い勝手をよくする方向⇒token 長を伸ばす。
・安くする方向⇒まったく新しいAIチップへの対応などで、 更に安くなる可能性があります。 nvidia は A100、H100 を計算力に比べてかなり高値で売りつけています。SambaNovaのような 非ノイマン型アーキテクチャを採用できるようになれば、10x以上安くなると予想しています。
スキル育成に生かすLlamaIndexの活用 大瀧隆太
クラスメソッドの大瀧さんのLlamaIndexの活用事例。当日の資料は下記。

DevelopersIO BASECAMPは、AWSを仕事で使うための体験型プログラムで、実践的なAWSの研修プログラムを提供。

そんなDevelopersIO BASECAMPを運営していく上での課題は以下。
- ロールプレイはWebミーティングやチャットによる同期的なやりとり
- 平日夜間、 土日の受講生の活動時間帯に合わせて運営メンバーが活動するのに大きな負担
- 次期以降、 受け入れ人数を増やしていきたい
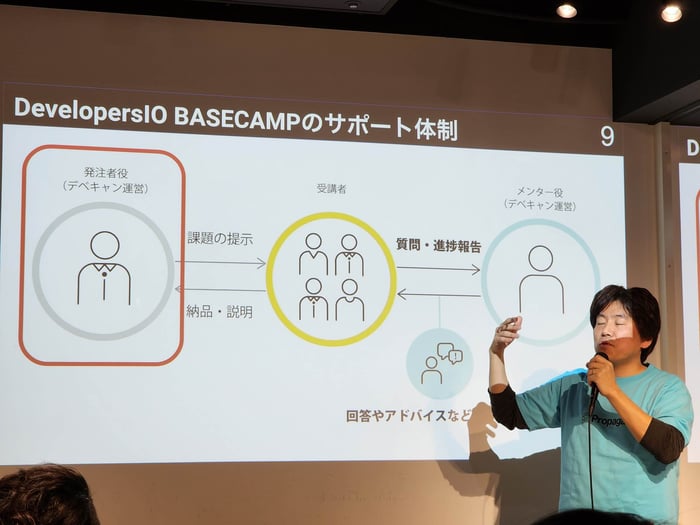
発注者(顧客担当者) 役は課題となる案件について 受講生から質問を受けたら答えるロールであるため、「案件情報以外を答える必要はない」「完璧な回答を一発で返す必要はない」ということから、OpenAI APIを利用したチャットボットを利用したらよさそうではないか、という発想になった。

今回の構成については、クラスメソッドのブログで公開中。
利用したLlamalndexはOpenAI APIで、ユーザー 独自のコンテキストデータを便利に使うためのPythonライブラリ。
●インデックス作成:コンテキストデータを関連性を持たせたインデックスに分割する
●クエリ:インデックスから質問文に関連するものをピックアップしてLLMに質問
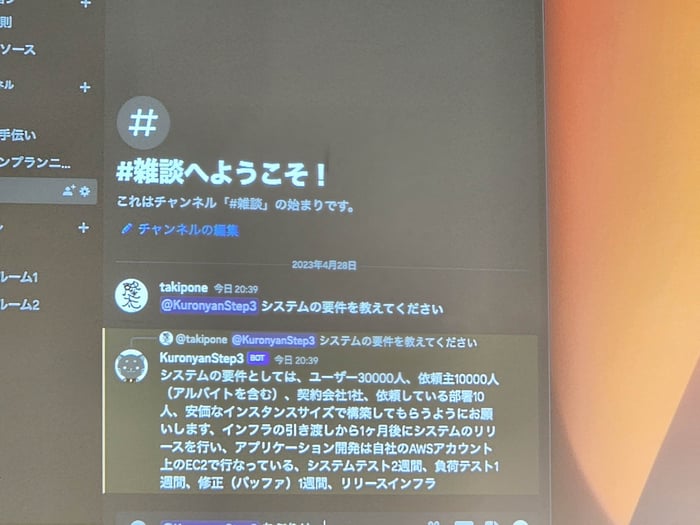
Slackでのデモ画面。「システムの要件を教えてください」という問いに答えている。
最後に発表のまとめ
- 課題の参考情報の提供手段としてチャットボット活用
- LlamaIndexでインデックス作成とクエリを簡単に実装
- プロンプトをカスタマイズして日本語の回答を得る
ChatGPTとWatson Discoveryでサイト内検索を進化させてみた 江頭貴史
サイト内検索サービスの実装事例。


これまで、サイト内検索には越えられない壁があった。
検索の利用側の想い
- 知りたいことだけ教えて
- 役立つことだけ教えて
- 検索結果の一覧を見て回るのは面倒でイヤ
提供企業側の想い
- 顧客の悩みを解決したい
- 製品やサービスをぜひ知ってもらいたい
- 購入してもらいたい
検索でできることは「検索結果の一覧表示、 選ばれた結果の内容表示、 条件の入力支援程度」であって、検索の利用側と提供企業側の想いをつなげられていない点が課題。こうした課題を解決するために、ChatGPTとWatson Discoveryでサイト内検索を進化させてみた。

品質の改善のために、実施したこと。検索精度や応答精度に満点はなく、利用者が入力する条件も検索対象のコンテンツも変動し、ChatGPTもWatsonもどんどん精度が上がり、結果が変わっていく。
そこで、定期的な精度把握とチューニングのサイクルが重要となってくる。具体的には、ログ管理機能やテスト条件セットによる自動テスト機能の搭載、チューニングの伴走支援や一括請負サービスをラインナップしている。
医療系スタートアップでのLLM PoCの共有と今後の取組 上野彰大
LINEから薬が買える医療系スタートアップでの活用事例。

YOJO薬局でのLLM活用シーンは、疑義照会。

医師が発行した処方せんの間違いなどを発見し、薬局から医師に問合せをすることが、疑義照会。疑義照会の7、8割ぐらいが、単純な記載ミスであるため、LLMが活用できるのではないかと考えた。
疑義照会の自動化に必要なステップ(今回は特に2と4でGPT-4のAPIを用いている)
- 処方せん情報をテキストデータ化する
- 処方せんのテキストデータから医薬品の処方情報を抜き出して構造化する
- 処方情報からその医薬品の添付文書を取得する
- 処方情報とその医薬品の添付文書を照らし合わせて疑義照会の文章を作成する

処方せんの書式は様々であるため、処方情報の抜出には工夫が必要。
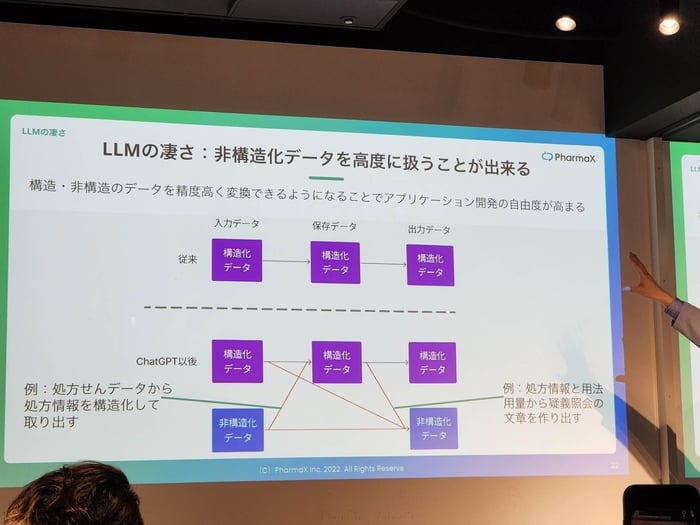
LLMの凄さは、非構造化データを高速に扱うことができる点。
処方せん内容だけでなく、服薬指導の音声から薬歴の自動生成を行っている。
最後に
GPUが大好きなだけあって、乾さんの発表は、ChatGPTに費やされているコストの計算が秀逸でした。ここまでコストがかかるAIをOpenAI Inc. が非常に安価な価格で公開している点に、ある種の哲学を感じました。誰もが最新のテクノロジーを使えるクラウドサービスとして提供してくれているわけですから、有意義に活用してそのノウハウを世の中に還元するのがEngineerの役割ではないかと思いました。
クラスメソッドの大瀧さんの発表、すごくわかりやすかったです。難しい技術を誰にでもわかりやすく説明する工夫が大瀧さんのブログからも感じられます。ChatGPTの回答の揺れを活かして、「完璧な回答を一発で返す必要はない」という利用シーンで使っている点に、センスの良さを感じました。他でも応用していきたいです。
江頭さんのサイト内検索では、「検索の利用側と提供企業側の想いをつなげられていないこれまでの課題」に着目した点、ユーザーインターフェイスの改善という意味で興味深かったです。文脈理解が得意なChatGPTと、IBM Watsonを組み合わせることで、使いやすいサイト内検索が作れそうで、試してみたいと思いました。
上野さんの事例は、医療のDXとも呼べるもので、もっと当たり前になっていくべき分野だと感じました。人間がすべての投薬の判断をするよりも、AIにアシストしてもらったほうが効率的だし、誤りも少なくなるはずです。オンラインでの診療ではどうやって薬を受け取ればいいのだろうかと思っていましたが、LINEで薬を受け取ることができれば簡単ですし、ぜひ使ってみたいと思いました。
ChatGPTの活用シーンはどんどん広がっていきそうです。引き続き、最新情報をキャッチアップしていきたいと思います。
