
はじめに
こんにちは、ネクストモードのSaaS事業部hagiです!
前回の記事で精神的に燃え尽きてしまった私ですが、語彙力とHHKBの感触を取り戻してまた戻ってきました。
お客様の後押しのおかげ様でもあるので、今回もまじめに書きたいと思います。
入れたら終わりじゃない。SaaSと生きるの始まり。
あつらえたように手に馴染むNetskopeですが、「トライアルをよく乗り越えた!本番導入頑張った!」で終わってはいけません。
念願のSaaSを手に入れて、従業員への展開が済んだら、今度はSaaSの利便性を享受していくフェーズが始まります。
ここからは、個人的にNetskopeと2.7年ほど過ごしてきて今、運用で変わったこと、変わらないことを書き殴っていきたいと思います。
なお、本記事に導入ナレッジは含まないため、運用時の気づきとなれば幸いですが、人が落ちる前にマンホールの穴を塞ぐような地味な作業が含まれます。よって誰にも褒められません。覚悟してください!
新規ポリシーを取り込むコツ
ポリシーチューニングの話をしても社内で乗ってくれる人があまり周りにいないという方はいらっしゃいますでしょうか。ぜひご相談ください!
かくいう私も私と活発にお喋りしているのですが、思いついたらとにかく自分にかけてみて、問題なければ最初の被害者(Netskopeに明るい人達が望ましい)にかけてみて、文句が出なかったら一方的に全体に当てています。
いちいち確認を待っているとセキュリティの脅威に追いつけませんし、またいらんことをしていると思われてしまうため、間髪入れずにどんどんメンバーにお見舞いしてあげています。一切バレずに全体まで当てられることが理想です。
基本的に、通常業務に支障がないかを確認したいため、適用の予告などはあまりしていません。
そして良い呪文ができたらお客様にも提案することもあります。
「何をそんなに取り込むことがあるんだ」と思われるかもしれませんが、普段生きているだけでさまざまな不正案件が上がってくるので、適用できそうなものをNetskopeに置き換えられる限り当てていっています。
特定のインシデントに悪気はないですが、直近で締め付けた挙動はGmail個人アカウントのLogin Attemptアクティビティです。

こちらもあくまでユースケースですが、プリセットのDLPでパスワード文字列のパターンを掴むことができるので、クレデンシャルをスラックに書くアクティビティを検出して楽譜を表示してみたって良いと思います。(WaTTsonさんの名曲をお借りします)


また情報収集に関して、よりオリジナルのソースに近い場所から取得したほうが早く知ることができるのですが、こちらはSOCチームを保有する組織の取り組みはマネできないので、適度にキュレーションされたものを取得することが望ましいです。
毎日見ていたら仕事ができなくなるソースの例:
- http://izumino.jp/Security/sec_trend.cgi
- https://www.bleepingcomputer.com/
- https://therecord.media/
- X(Twitter)
シャドーITと対話する
シャドーITとは、組織で認可されていなかったり、組織が把握できていない個人のIT利用を指します。
最近のコンシューマー向けセキュリティスイート製品では、アンチウイルスだけでなくWeb脅威のブロックや、Cookieのお掃除、ダークウェブ監視やパスワードマネージャーまで付いているようですが、ログインアカウントまで可視化できる製品はまだ見たことがありません。
そこでCASBニーズでどんどんお声がけをいただいているNetskopeの登場なのですが、制御をしなければ宝の持ち腐れです。
認可されていないSaaS、認可されているSaaSだけど違うアカウント、認可されていないSaaSけど認可されているアカウント、だんだん混乱してきますが、従来の働き方では静的URLでブロックをするところ、柔らかい目線でログは取られてるんだぞという前提で、働きやすさを皆さん改善していきたいはずです。一番多い課題は、体外との認可ツールの差異ですが、なぜシャドーITに注目しているのか、バッドパターンを抽出して、特定の条件だけを締め付けるだけに留めることで、体外と摩擦なくやり取りができるのだという大義名分で日々チューニングを行っています。
パターンの抽出は能動的に行わなければなりません。ポリシー化する前のシャドーITは管理者からはただのログにしか見えないので、シャドー利用のケースを待っていても来ないし、要望してくれと言ってもきれいなジャイアンみたいな回答をされて肩透かしを食らうだけだと思います。
ちなみに我々は、そのお手伝いができます。
NetskopeのUEBAである機械学習とユーザスコアリングに頼ってみるのも良いと思います。
一方、シャドーITから得られることもあります。
Skope ITやCCI(Cloud Confidence Index)から学べることがあります。
- このSaaSの画像アップロードはUploadじゃなくてPostアクティビティで投げてるんだ
- Slackハドルは中でAmazonChimeにコールしてるんだ〜
- アクセス先はS3なのにApplicationはAsanaとしてちゃんと認識するんだ
上記はよりマクロに情報をトレースしていった場合ですが、逆にログを人間に太刀打ちできない粒度にまでサマライズしてくれるAdvanced Analyticsで新しい気づきを得られるパターンもあります!
これは、AWSサービス系のインスタンス識別など、Sanctionedかどうかを見分けるので疲弊しそうになった際にも活躍します。
ポリシーの並びについて
Real-time Policyの並び順については公式からベストプラクティスも出ています。
なおTIPSですが、"Best Practices"でDocsを検索すると、多方面のBest Practicesが検索に浮かび上がってくるので全部読んで下さい。
なになに、資料によると、上段にマルウェア系やリスク通信のBlockポリシーを置いて、下部にCASB、CCIで得られる情報を元にしたポリシーやカテゴリベースのものを敷くと良いみたいですね。
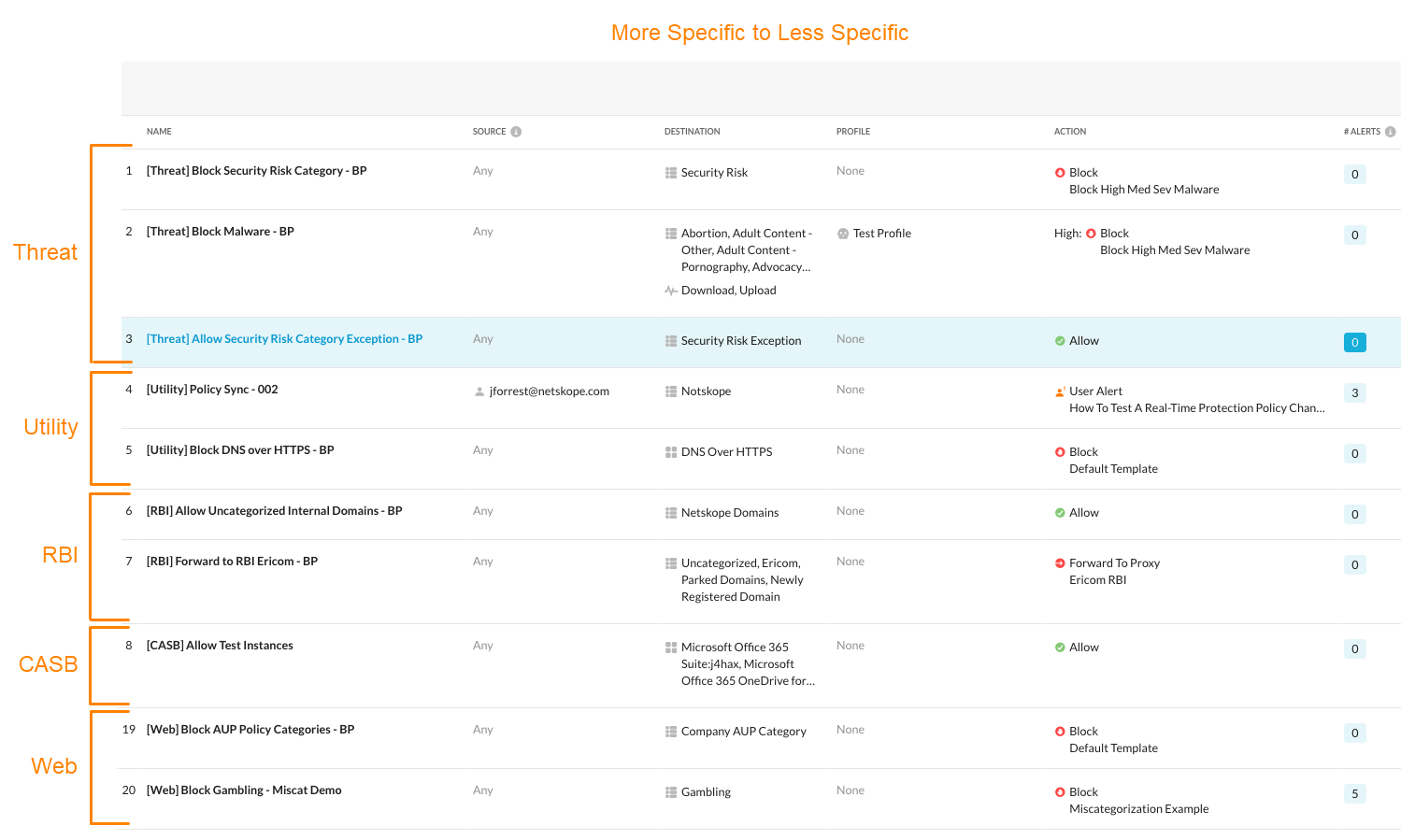
このようなピラミッドも図示されています。

このルールは必ずしも絶対ではないと思います。実現したい要望に応じて適宜組み替えて良いと思います。
ピラミッドといえば、一時期、独自の並び順を示した最強の墓場、私のピラミッドと呼べる構造体を造ったことがあるのでそちらも貼っておきますね。
違いが分かるでしょうか。ピラミッドを上から見た図ではなく、こちらは内部に条件付きポリシーを意図的に織り交ぜて、少ない行数に押し込められるよう配慮しつつ、未知の通信を定期監査で無くしていく目論見があります。Instance,Constraint,Category,Activity,SanctionedとUnsanctionedを両方使って時系列で並んだ時に一番最適となる順番で適当に当てていきます。Categoryによって利用できるActivityが変動するため、のめり込むと週末が加速していきます。
届く人に届けば幸いです。また、目に優しくないデザインにご注意ください。

ポリシー修正のコツ
初期導入時に実装したポリシーに修正を行いたくなる衝動に駆られることもあります。
順番を入れ替えたり…。ネーミングルールを変えてみたり…。
当初はキッチリ履歴を残してNotion DBで管理しようと心に決めていましたが、職業上なのか、管理者が複数になってくると統制が取れないことが分かってきます。
この話は新しい話ではありません。八百万のおじ、おばたちが経験したことがあると思います。 管理表のデグレです。
しょぼくれた管理表がどこかに置いてあったところで、(通知したとしても)誰も見ないし。
- メモの残骸

そういえば、Real-time Policyは、いつ頃からかエクスポートが可能になったんですよね。
これをJSON形式で吐き出して、社内のソースコード管理に食わせてあげれば差分管理ができることが分かり、こちらも試していました。


ただし結果は変わりません!ヒューマンが管理フローに挟み込まれている以上、漏れが発生します。
最終的に落ち着いた手法は、POLICY DESCRIPTIONへの経緯の記載でした。これくらい設定と近い位置にあれば流石にみんな見るでしょう!

忙しく駆け巡る社内事情に追従するため、実機=正に最適化されました(怠けてない)。
Descriptionから経緯が把握できたらあとはこっちのもんです。実機にパラメタが載っているんですから。
ダサくないダサくないダサくない!
ほら、ダサくない。
業務外カテゴリの扱いについて
箸休めですが。
業務外カテゴリ(ギャンブル、ドラッグ、アルコールなど)について、以前は取引先との兼ね合いで業務カテゴリとなり得る場合もあるんじゃないかというのもあり、User Alertsにして本人にお任せしていたのですが、推しツヨなメンバーによりBlockに倒されました。案外何ともなかったです。
とはいえ、業務影響の有無は常に気にしています。
現在社内では何かあればすぐにSlackで呼びかけてよいムーブになっています。
切り分けが必要であれば個別条件を切って対処します。
そのくらいの俊敏さ、柔軟さで、全国各地でリモートワークしているメンバー各位にフォローの対処が行えるのも良いところだと思っています。
ただし一人情シスの方などは受けきれないと思いますのでこれらをBlockに倒すことはあまりおすすめしません。
レポート運用について
Reportsの定期出力は、日常から少し距離を置いて俯瞰できるためおすすめです。
メールにPDF添付されて来るようにすることも出来るので、ログインで待たされることもありません。
総量を示す棒グラフも良いですが、せっかく長期スパンで出力するのであれば、時系列が分かるような折れ線グラフを用いると見るべきログを絞りやすいです。

アラートの数や、シャドーITの件数を出力するのが一般的ですが、下記のようなレポートも試してみてください。
- Total Eventsから業務のしんどさを可視化
- 好きなSaaSどれが人気かアクティビティの件数で戦わせてみる
- SaaSの裏側(CSPプロバイダやHosting Location)
トラブル時の対応について
最後にトラブル時の対応についてですが、コツとしてはすぐに通信から除外設定しようとしないことです。リモート対応中に通信除外してしまうと、通信影響がなくなるのと引き換えに問題をないがしろにしてしまうため、原因が分からず時間だけが過ぎていき、解決までの時間が余計にかかってしまうこともありえるからです。
また例えがアレですが、ソーシャルエンジニアリングで従業員になりすました脅威アクターがITサポートにイレギュラーな問い合わせをする手口は不正アクセスの常套手段として未だにメジャーであるため、管理者の責任問題になると言えます。
いざ、通信除外といっても強度を変えて、ユーザー指定できるならした上でインスタンス指定除外、App指定除外、SSL除外、プロセス除外、宛先除外などの選択肢から軽微で済む手法を切り分けながら選択していくのはいかがでしょうか。
事前に管理側で、常時除外した宛先を用意してあげて、そちらと(スループット等)比べて切り分けていただくなども有用です。
やむを得ず除外する場合も、除外していないSaaSで何か傾向が変わることもあるので当該ユーザーのデータの出入りをレポートしておくことも可能です。
穴を開けた分、多層防御で他製品でカバーできる環境づくりも心がけたい次第です。
案外事情を聞いてみたら、対処がいらなかったということもあります。ヒアリングしてみると良いと思います。
下記は昔作った切り分け用のヒアリングシートですが、すぐに会話を繋いで話せる環境であれば、そちらのほうが申告側も負荷が少なく、画面共有で状況を見せられた方が捗るはずです。

さいごに
私は仕事柄なのかSaaSを評価する使命感にかられているため、今後も人一倍いらない通信を発生させ続けながらSaaS可視化の探求を続けていきたいと思います。