
こんにちは、ネクストモード株式会社の平林です。
今回は、S3のマウントポイントをテーマにした「Optimizing throughput performance using Mountpoint for Amazon S3 (STG343)」 に参加してきました。
スピーカーと参加者で対話しながら進めるChalk Talk形式で行われ、
通常のスライドセッションでは聞けない裏話や、参加者の素朴な疑問にもエンジニア同士で深く議論する、非常に濃密なセッションでした。
セッション概要
まずはセッションの基本情報です。
- セッションID:STG343
- セッション名:Optimizing throughput performance using Mountpoint for Amazon S3
- 形式:Chalk talk
- レベル:300 – Advanced
- スピーカー:Fuat Basik、Ankit Kalyani
今回の目次です。
- Mountpoint for Amazon S3 のようなクライアントコネクタがなぜ必要なのか
- なぜストレージパフォーマンスが重要なのか
- Mountpoint は何をしてくれるのか
- Mountpoint でスループット性能を最適化するためのベストプラクティス
- デモ
Mountpoint for Amazon S3 のようなクライアントコネクタがなぜ必要なのか

クライアントコネクタを「海外旅行用の電源変換アダプター」に例えて
MountpointはS3のAPIを使えない既存のアプリケーション(プラグ)と、S3(壁のコンセント)の間に入り、
インターフェースを変換して接続可能にする役割があります。
なぜストレージパフォーマンスが重要なのか

Faster Workloadsは顧客体験の向上やイノベーションの加速に繋がります。
Better compute utilizationは速ければ計算リソースの待ち時間が減り、結果としてトータルコストが削減できます。
Mountpoint は何をしてくれるのか

Mountpointの活用例として馴染みがあるものは自動運転シミュレーション、機械学習トレーニング、画像トランスコーディングのようなものがあり、
ファイルAPIをS3 REST APIに変換するオープンソースのファイルクライアントであることや、高スループットと高い信頼性を持ち合わせています。

MountpointはAWS Common Runtime上に構築されており、
S3へのアクセスに必要な再試行、タイムアウト、並列処理などのベストプラクティスが自動的に組み込まれています。
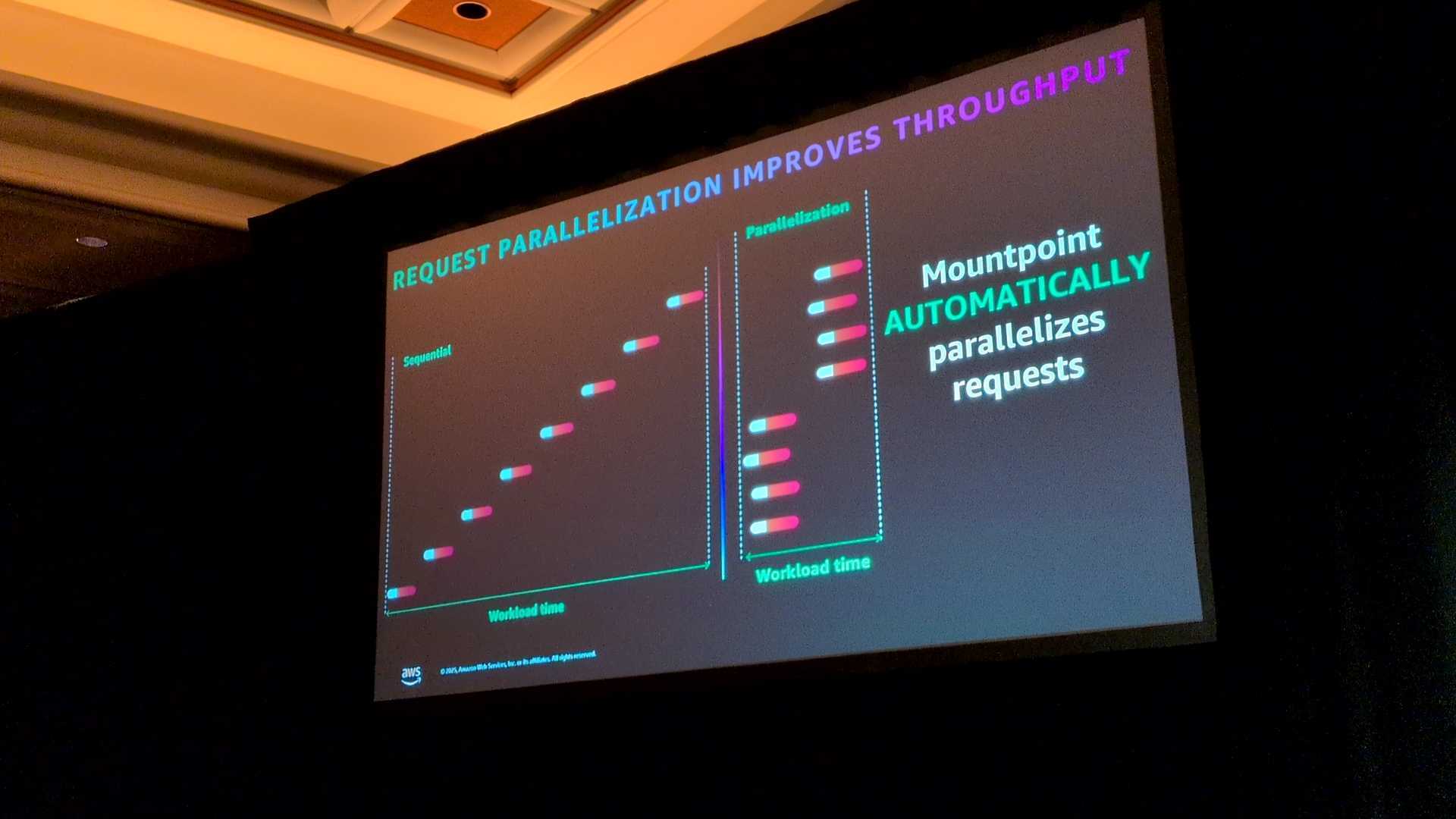
リクエストを1つずつ順番に処理するのは非効率です。
Mountpointは自動的にリクエストを並列化し、S3の高い弾力性を活かしてスループットを最大化します。
Mountpoint でスループット性能を最適化するためのベストプラクティス
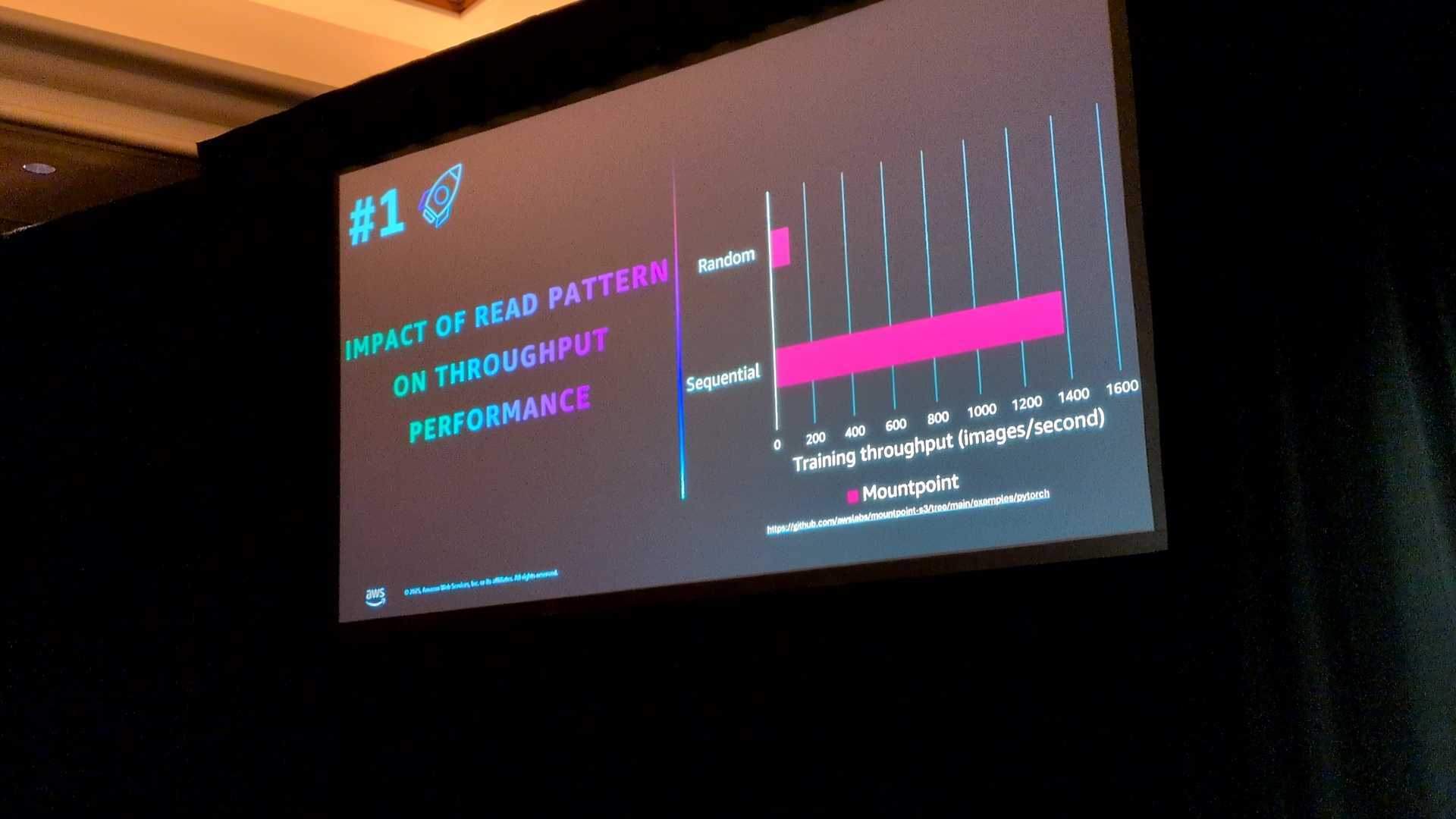
ランダムアクセス(上段)よりもシーケンシャルアクセス(下段)の方が、プリフェッチ機能が効くため圧倒的に高速です。

Mountpointは、シーケンシャルなアクセスを検知すると、アプリが現在のデータを処理している間に、裏側で次のデータを先回りして取得します。
これにより、CPUやGPUを待たせることなくデータを供給できます。

繰り返しアクセスするデータをローカル(メモリ/ディスク)にキャッシュすることで、最大2倍の高速化が可能です。
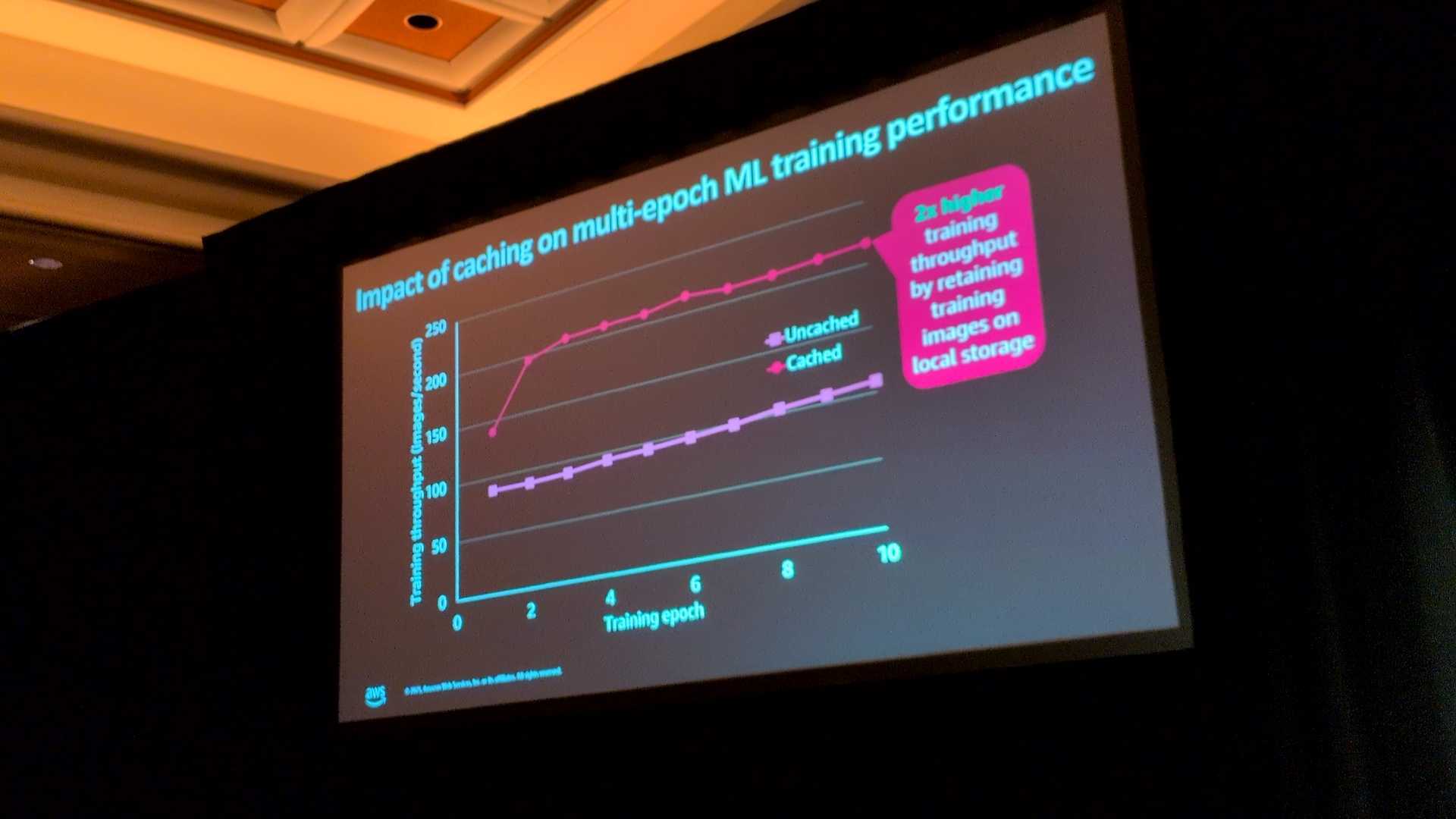
Mountpointのキャッシュ機能における隠れたメリット(メタデータキャッシュ)について
- 1回目の読み込み(Epoch 1)から高速化する理由
通常、キャッシュの効果はデータを再読み込みする2回目(Epoch 2)以降に期待されますが、実際には1回目の時点でもパフォーマンスが向上します 。
- メタデータキャッシュの効果
メタデータがキャッシュされるためです。
ListObjectの結果がキャッシュされることで、S3へのHeadObject リクエストを行う必要がなくなり、その分の処理時間が短縮されます 。
- 重要な活用ポイント
データサイズが大きすぎてディスクに全てキャッシュできない場合や、繰り返し読み込みを行わないワークロードであっても、
データ本体よりはるかに軽量な「メタデータキャッシュ」のみを有効にすることで、パフォーマンス向上の恩恵を受けることができます 。

Mountpointは回線を束ねることができるため、より高価なGPUインスタンスでも帯域幅を最大限に活用できます。

先月、Mountpointの監視機能が追加されました。
これによりCloudWatchやPrometheus、Grafanaなどの監視サービスから直接、Mountpointのメトリクスを確認できるようになりました。

今年、CSI Driverのメジャーアップデート(v2)が行われ、アーキテクチャが刷新されました 。
新しいアーキテクチャでは、Mountpointがノード上のコンテナで起動するようになりました 。
これにより、同じノード上で稼働する複数のPODが、Mountpoint自体とそのローカルキャッシュを共有できるようになります。
その結果、一度S3からダウンロードされたデータは、同じノード上の他のPODからも利用可能(キャッシュ共有)となり、効率が向上します。
デモ
画像認識モデルのトレーニングを題材に、
Mountpoint for Amazon S3の設定やデータ構造の違いがパフォーマンス(GPU使用率と処理速度)にどう影響するかを実演しました。
- シナリオ 1(No Caching):最適化なし
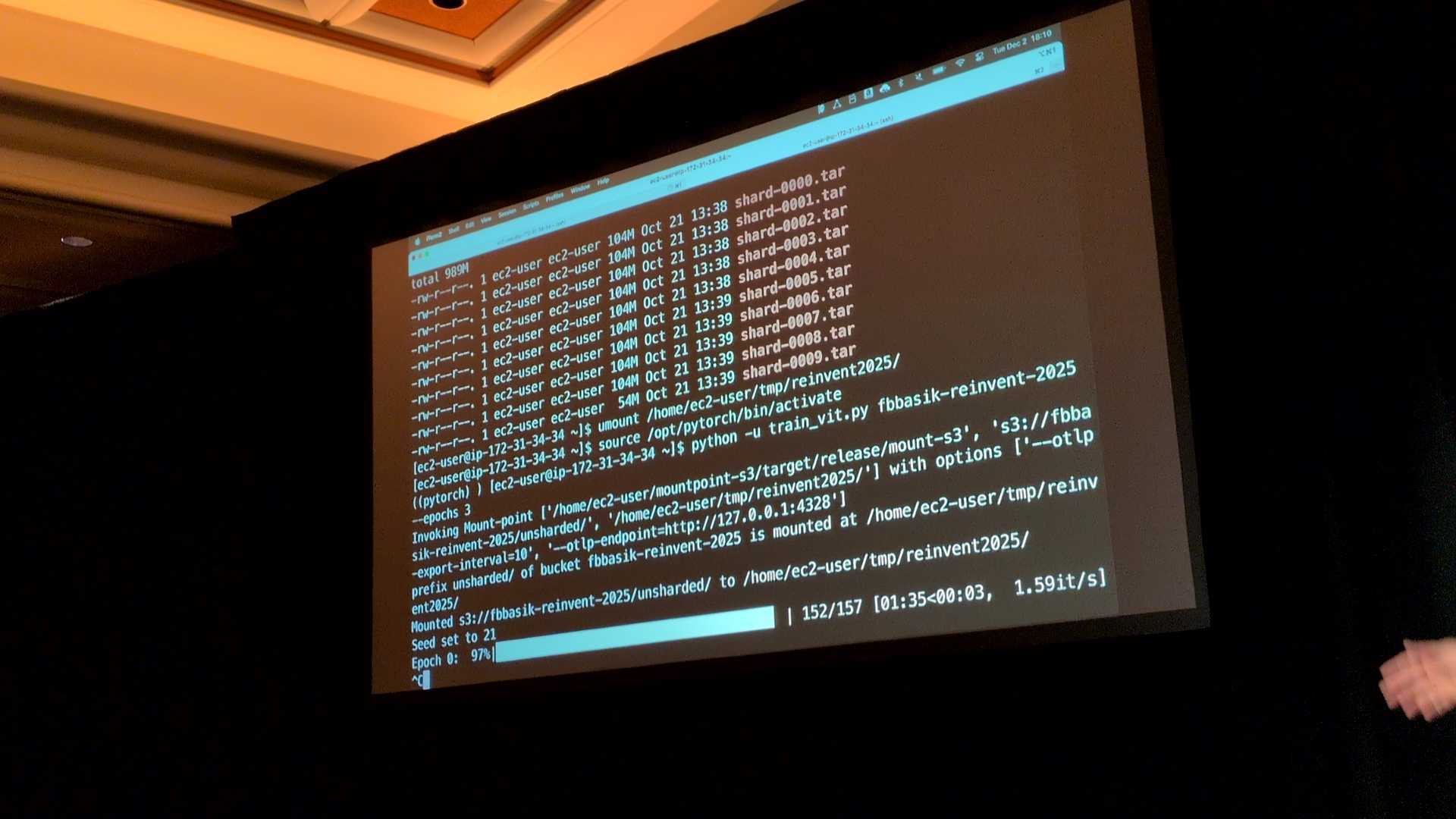
設定としては、Unsharded(小ファイル群)を使用し、キャッシュや特別な最適化フラグはなしで実行します。
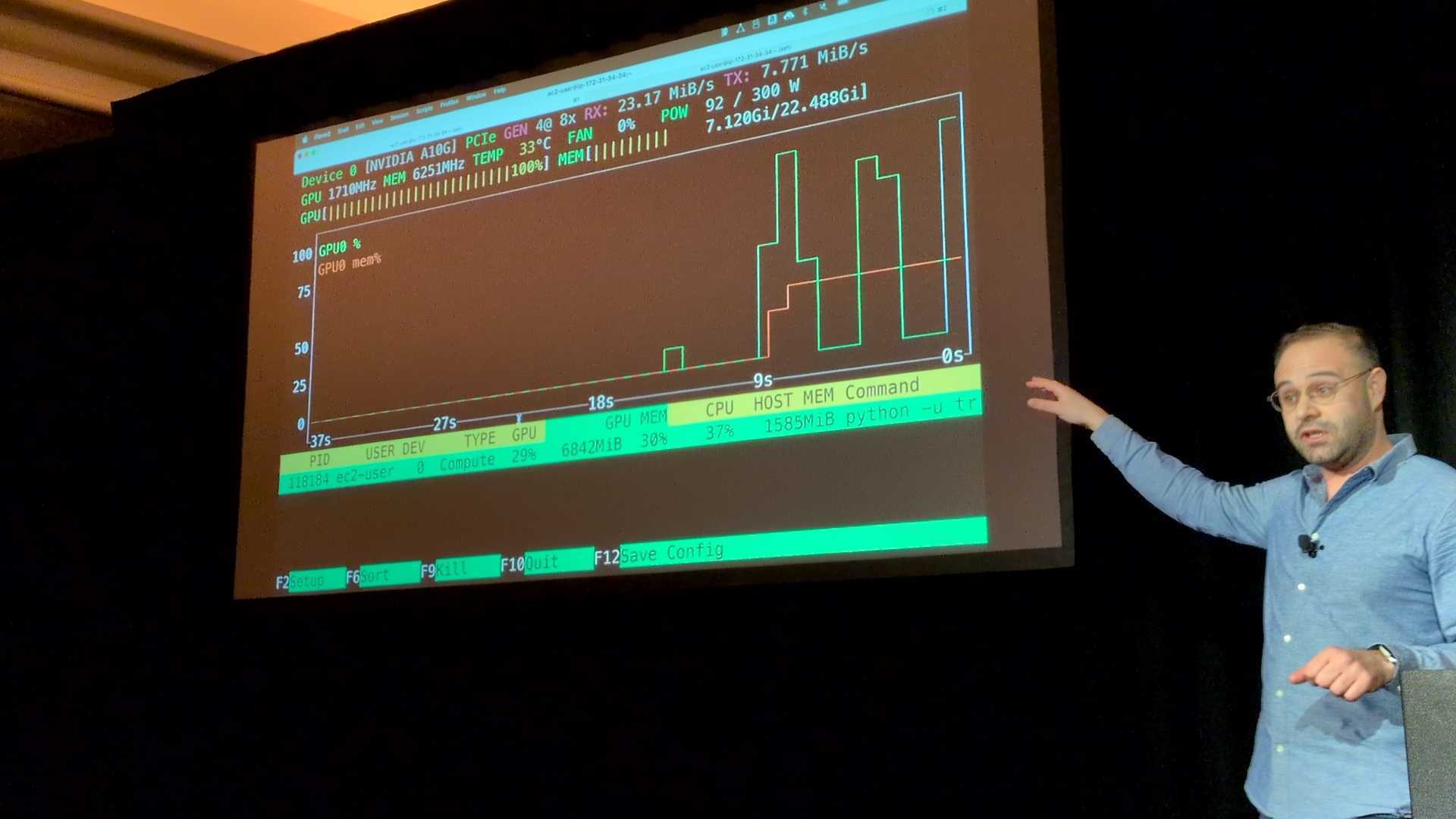
結果としては、GPU使用率は激しく変動し、頻繁に0%に落ちる(アイドル状態が発生) 、処理速度は1.59it/s程度。
原因としては、ファイルが小さく大量にあるため、1つずつS3へリクエストを送るオーバーヘッドが大きい。
そのためデータの到着待ちが発生し、GPUが「飢餓状態(Starvation)」になっている。
- シナリオ 2(Caching):キャッシングの有効化
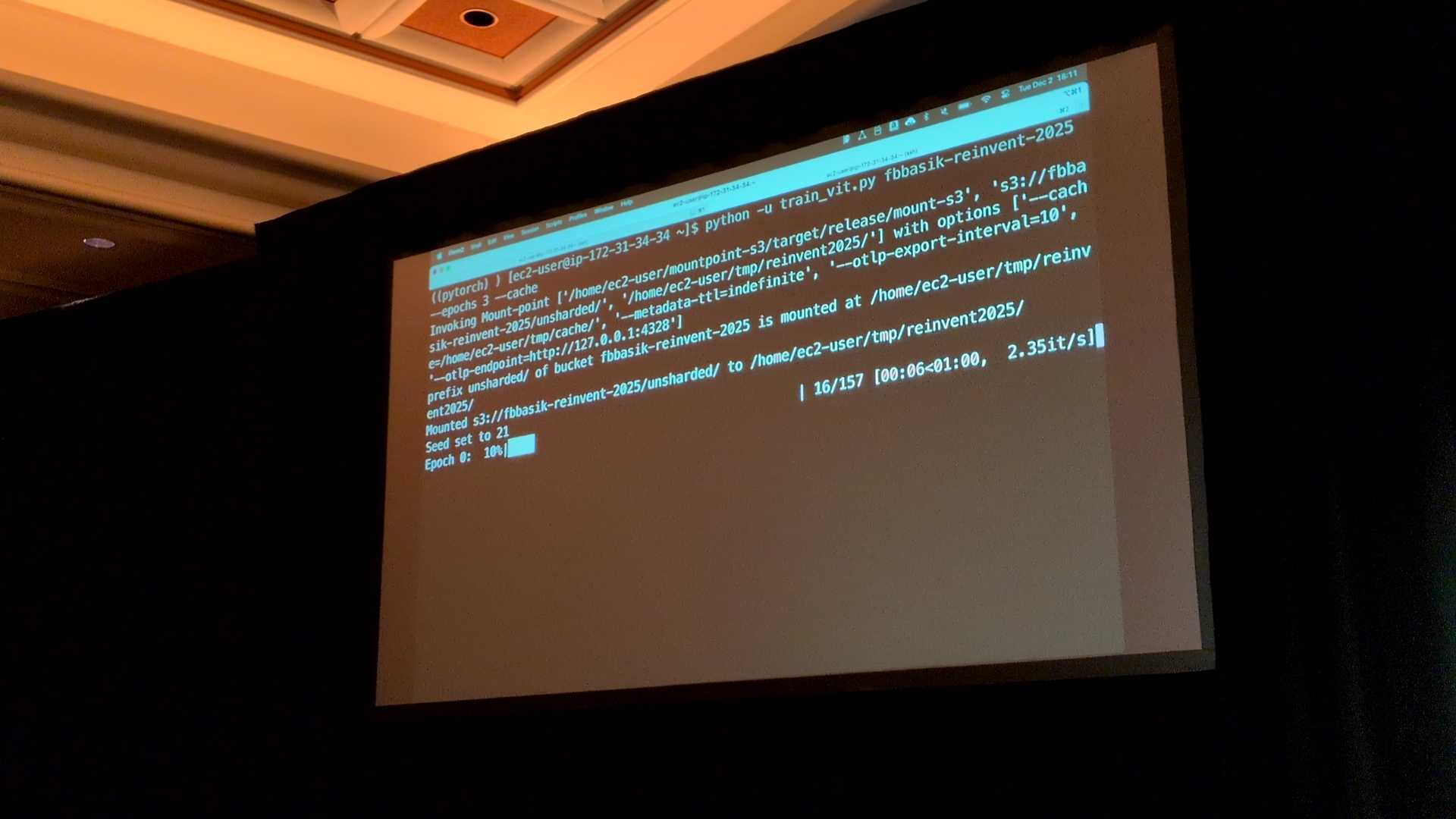
設定としては同じく「Unsharded(小ファイル群)」を使用。
Mountpoint起動時に --cache フラグを追加して再度実行します。
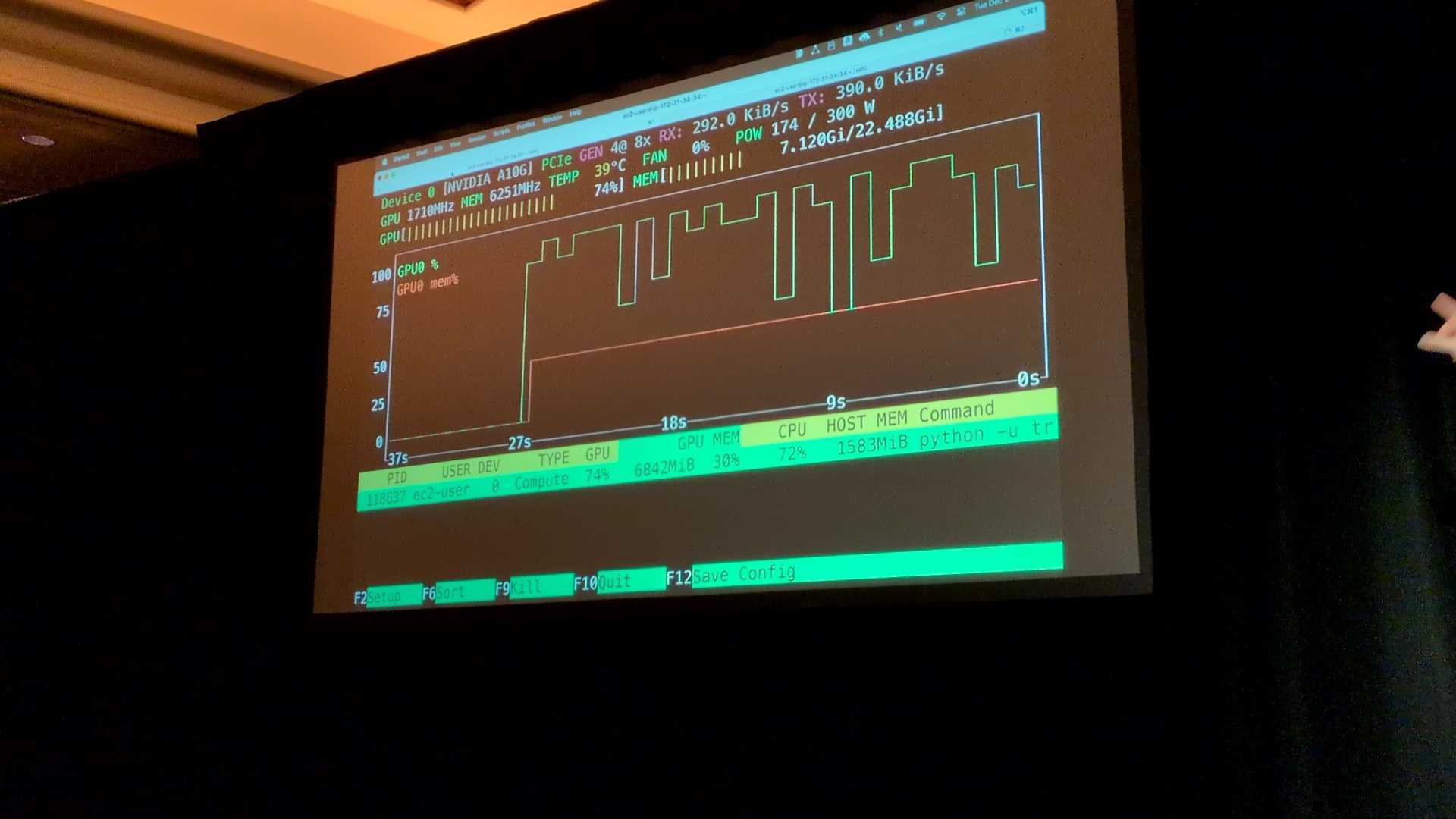
1回目のEpochでは処理速度は2.35it/sに向上 。
理由はメタデータキャッシュが効いており、HeadObject(ファイルの属性確認)のリクエストが省略されるため 。
2回目以降のEpochではGPU使用率は100%に張り付いている。
理由はデータがローカルディスクから読み込まれるため、S3へのネットワーク通信が発生しない 。
- シナリオ 3(Sharding):シャーディングとプリフェッチ
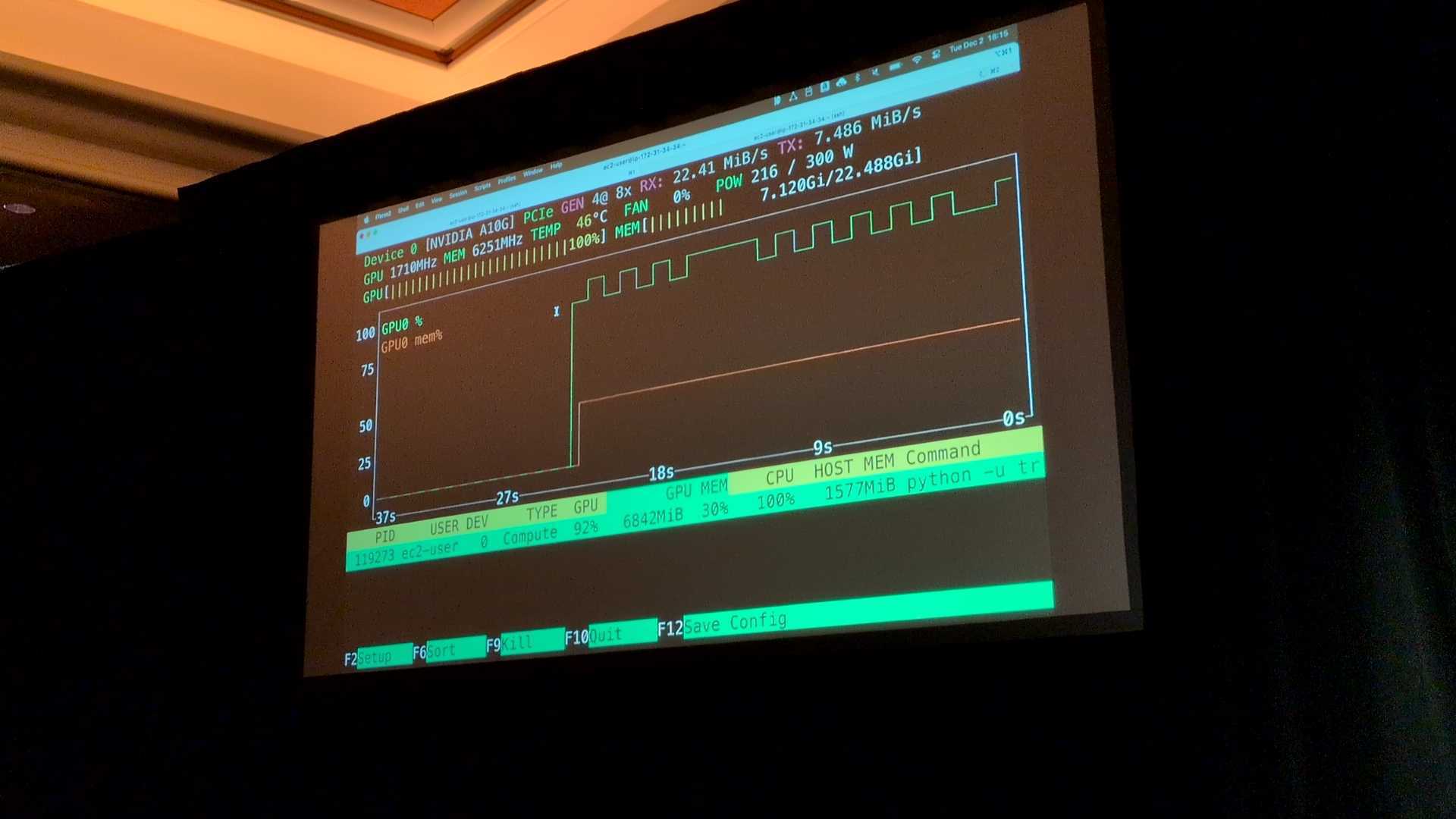
Sharded(TARファイル化したデータ)を使用し、純粋なデータ構造の効果を見るため、あえてキャッシュは無効化
GPU使用率は開始直後から安定して100%を維持。
処理速度は高速である。
原因はファイルサイズが大きくなったことで、Mountpointのプリフェッチ(先読み)機能が有効に働いたため。
シーケンシャルにデータを読み込めるため、計算リソースを待たせることなくデータを供給できた。
- 各シナリオごとの比較(GPU)
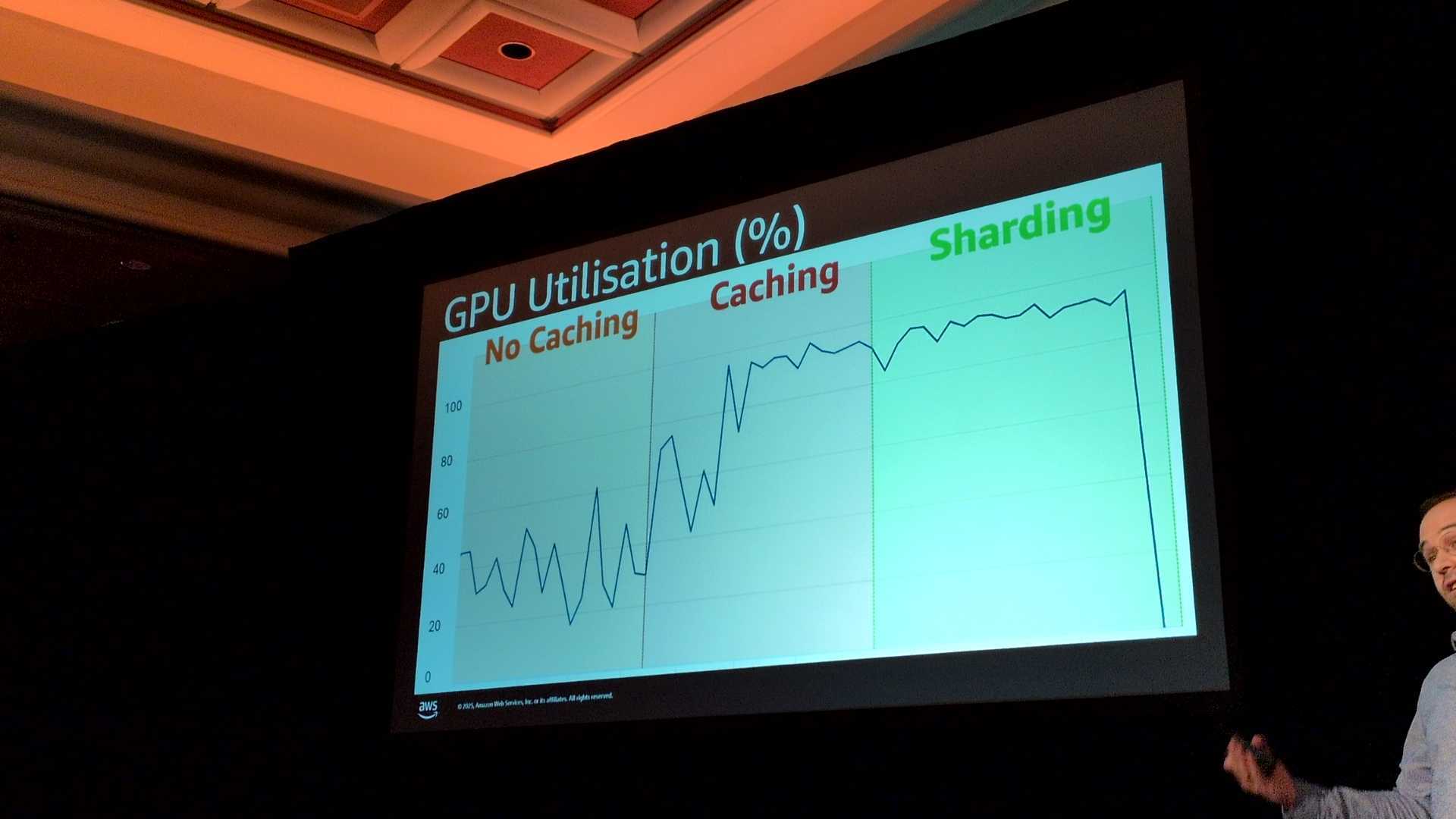
シナリオ1ではGPU使用率が低く、処理時間の半分はS3のデータ待ち(アイドル状態)が発生していると指摘しています。
- 各シナリオごとの比較(S3 Requests)

シナリオ1は1分間に16000件以上のリクエストがあり、学習トレーニングの負荷に対応していました。
シナリオ2では予想通り、
最初のEpochと2回目以降はHeadObjectリクエストは行わず、ローカルディスクからデータを提供しているため、リクエストを行いません。
シナリオ3は非常に低く、リクエストは10件程度です。
- 各シナリオごとの比較(Network Bytes In)
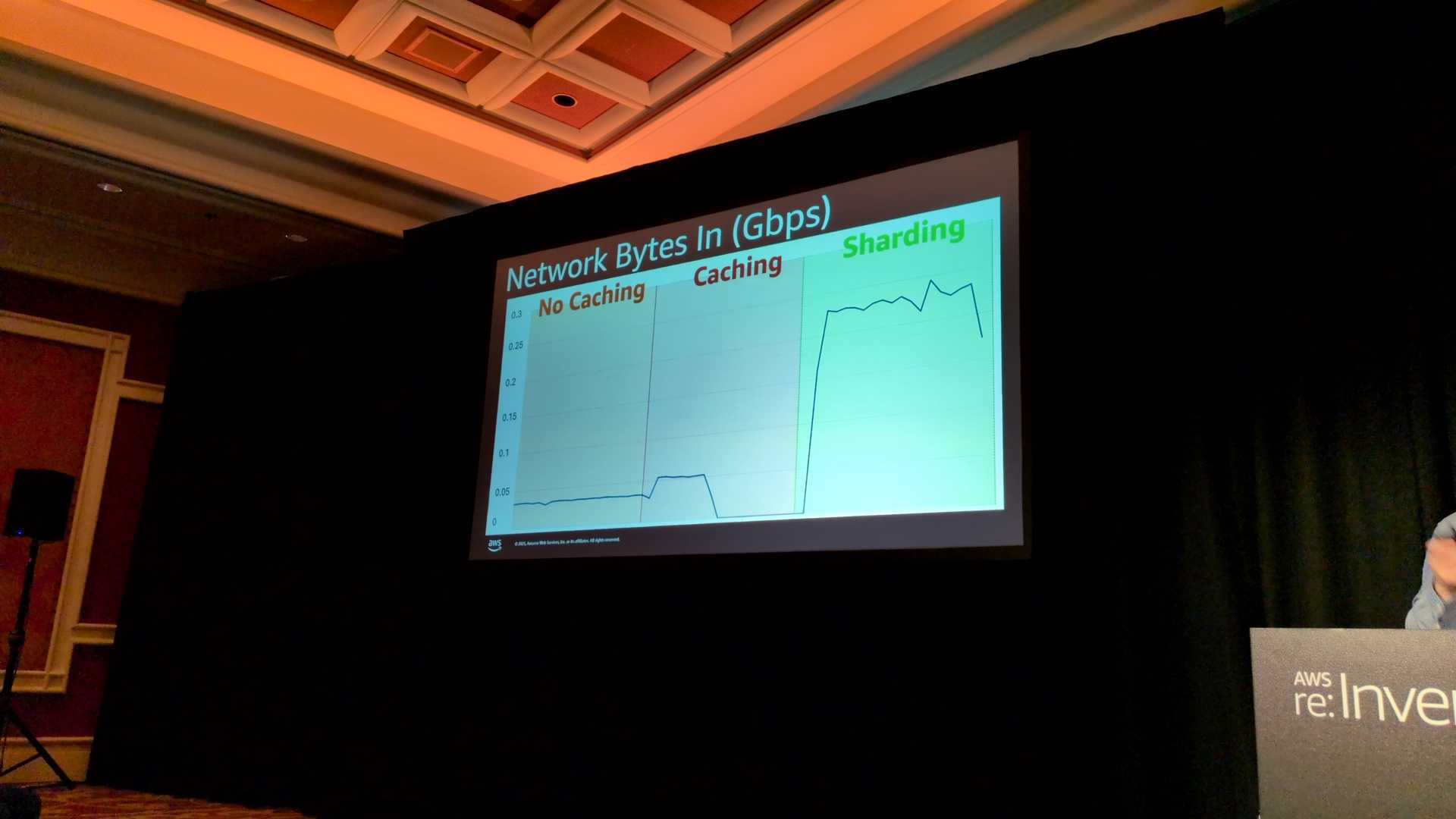
シナリオ1では低い位置で推移しています。
理由としては小さなファイルを個別に取得しているため、レイテンシー(待ち時間)がボトルネックとなり、ネットワーク帯域を使い切れていません。
シナリオ2では最初だけ少し波があり、その後はほぼゼロになっています。
理由としては最初のEpochでデータをダウンロードした後は、ローカルディスクのキャッシュからデータを読み込むため、
S3へのネットワークアクセスが発生しなくなっています 。これによりネットワーク負荷がなくなります。
シナリオ3では最も高く、0.25 Gbps以上で推移しています。
理由としては小さなファイルを大きなTARファイルにまとめ、シーケンシャルに読み込むようにしたためです。
これにより、MountPointのプリフェッチ機能やリクエストの並列化が効果的に働き、ネットワーク帯域を最大限に活用できています 。

Mountpoint for Amazon S3は万能なファイルシステムではなく、以下のような特性を持つワークロードに適しています。
- 大容量オブジェクトの読み取り特化(巨大なオブジェクトに対する読み取り頻度が高いワークロードであること)
- 高弾力なスループットの享受(S3が持つ伸縮自在で高いスループット性能の恩恵を自動的に活用できること)
- 大規模なインスタンススケーリング(数千のインスタンス規模で柔軟にスケールアップ・ダウンが可能であること)
- 書き込みアクセスの単一性(多数のインスタンスから読み取る一方で、特定ファイルへの書き込みは単一インスタンスから行われること)
まとめ
Mountpoint for Amazon S3がオープンソースプロジェクトであることが強調されました 。
開発チームはユーザーからのフィードバックや、実際のワークロードでの設定例の共有を求めています 。
もし機能要望や改善点があれば、ぜひGitHubのリポジトリを通じて声を届けてみてください 。もちろん、AWSサポートを通じての問い合わせも可能です。
読み取り中心のワークロードにおいて、キャッシュやシャーディングを駆使することで劇的なパフォーマンス向上が見込めるこのツール です。
ぜひ実際に試し、その知見をコミュニティに還元してみてはいかがでしょうか。
このブログがS3のパフォーマンスを最大限に引き出すための一助となれば幸いです!